Part 3 : Mitigate Bias, Train another unbiased Model and Put in the Model Registry
Overview
Notebook 2: Train, Check Bias, Tune, Record Lineage, and Register a Model
`Notebook 3: Mitigate Bias, Train New Model, Store in Registry <./3-mitigate-bias-train-model2-registry-e2e.ipynb>`__
`Architecture <#train2>`__
`Develop a second model <#second-model>`__
`Analyze the Second Model for Bias <#analyze-second-model>`__
`View Results of Clarify Bias Detection Job <#view-second-clarify-job>`__
`Configure and Run Clarify Explainability Job <#explainability>`__
`Create Model Package for the Second Trained Model <#model-package>`__
Notebook 5 : Create and Run an End-to-End Pipeline to Deploy the Model
In this notebook, we will describe how to detect bias using Clarify, Mitigate it with SMOTE, train another model, put it in the Model Registry along with all the Lineage of the Artifacts created along the way: data, code and model metadata.
Install required and/or update third-party libraries
[ ]:
!python -m pip install -Uq pip
!python -m pip install -q awswrangler==2.2.0 imbalanced-learn==0.7.0 sagemaker==2.41.0 boto3==1.17.70
Import libraries
[ ]:
import json
import time
import boto3
import sagemaker
import numpy as np
import pandas as pd
import awswrangler as wr
import matplotlib.pyplot as plt
from imblearn.over_sampling import SMOTE
from sagemaker.xgboost.estimator import XGBoost
from model_package_src.inference_specification import InferenceSpecification
%matplotlib inline
Load stored variables
Run the cell below to load any prevously created variables. You should see a print-out of the existing variables. If you don’t see anything you may need to create them again or it may be your first time running this notebook.
[ ]:
%store -r
%store
Important: You must have run the previous sequential notebooks to retrieve variables using the StoreMagic command.
Set region, boto3 and SageMaker SDK variables
[ ]:
# You can change this to a region of your choice
import sagemaker
region = sagemaker.Session().boto_region_name
print("Using AWS Region: {}".format(region))
[ ]:
boto3.setup_default_session(region_name=region)
boto_session = boto3.Session(region_name=region)
s3_client = boto3.client("s3", region_name=region)
sagemaker_boto_client = boto_session.client("sagemaker")
sagemaker_session = sagemaker.session.Session(
boto_session=boto_session, sagemaker_client=sagemaker_boto_client
)
sagemaker_role = sagemaker.get_execution_role()
account_id = boto3.client("sts").get_caller_identity()["Account"]
[ ]:
# variables used for parameterizing the notebook run
model_2_name = f"{prefix}-xgboost-post-smote"
train_data_upsampled_s3_path = f"s3://{bucket}/{prefix}/data/train/upsampled/train.csv"
bias_report_2_output_path = f"s3://{bucket}/{prefix}/clarify-output/bias-2"
explainability_output_path = f"s3://{bucket}/{prefix}/clarify-output/explainability"
train_instance_count = 1
train_instance_type = "ml.m4.xlarge"
claify_instance_count = 1
clairfy_instance_type = "ml.c5.xlarge"
Architecture for this ML Lifecycle Stage : Train, Check Bias, Tune, Record Lineage, Register Model
overview
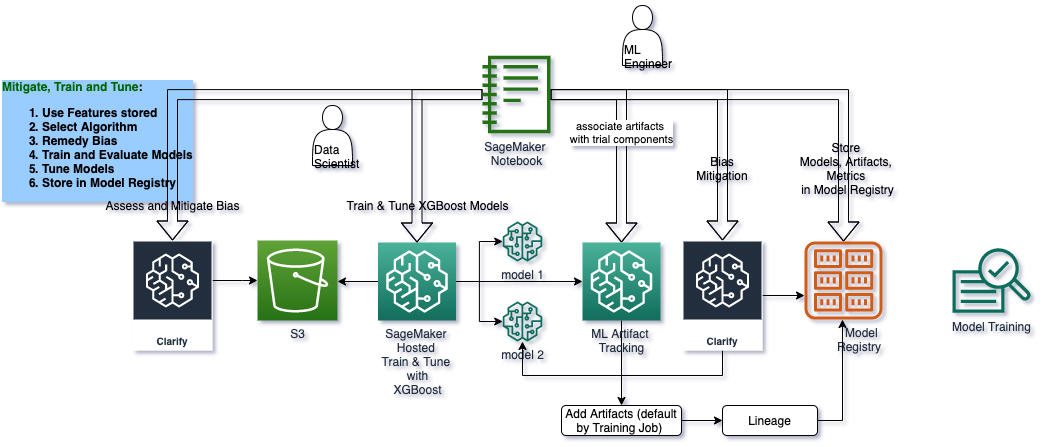
Develop a second model
overview
In this second model, you will fix the gender imbalance in the dataset using SMOTE and train another model using XGBoost. This model will also be saved to our registry and eventually approved for deployment.
[ ]:
train = pd.read_csv("data/train.csv")
test = pd.read_csv("data/test.csv")
[14]:
train
[14]:
| fraud | vehicle_claim | driver_relationship_self | num_witnesses | policy_deductable | incident_day | policy_state_nv | policy_state_az | auto_year | policy_state_or | ... | authorities_contacted_police | total_claim_amount | incident_hour | policy_state_ca | injury_claim | authorities_contacted_ambulance | policy_annual_premium | customer_gender_male | driver_relationship_other | num_claims_past_year | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 21500.0 | 1 | 5 | 750 | 24 | 0 | 1 | 2012 | 0 | ... | 1 | 23000.0 | 20 | 0 | 1500.0 | 0 | 2450 | 1 | 0 | 0 |
| 1 | 1 | 16000.0 | 1 | 1 | 750 | 5 | 0 | 0 | 2017 | 0 | ... | 1 | 16000.0 | 8 | 0 | 0.0 | 0 | 2600 | 0 | 0 | 0 |
| 2 | 0 | 4000.0 | 1 | 2 | 750 | 19 | 0 | 0 | 2009 | 0 | ... | 0 | 4000.0 | 5 | 1 | 0.0 | 0 | 2450 | 1 | 0 | 0 |
| 3 | 0 | 19500.0 | 1 | 1 | 750 | 4 | 0 | 1 | 2018 | 0 | ... | 1 | 19500.0 | 13 | 0 | 0.0 | 0 | 3000 | 1 | 0 | 0 |
| 4 | 0 | 9500.0 | 1 | 0 | 750 | 22 | 0 | 0 | 2012 | 0 | ... | 0 | 9500.0 | 20 | 1 | 0.0 | 0 | 2750 | 1 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3995 | 0 | 9500.0 | 0 | 3 | 750 | 22 | 0 | 0 | 2014 | 0 | ... | 1 | 9500.0 | 9 | 1 | 0.0 | 0 | 3000 | 0 | 1 | 0 |
| 3996 | 0 | 8500.0 | 1 | 3 | 750 | 12 | 1 | 0 | 2015 | 0 | ... | 1 | 8500.0 | 22 | 0 | 0.0 | 0 | 3000 | 0 | 0 | 0 |
| 3997 | 0 | 12000.0 | 1 | 1 | 750 | 15 | 0 | 0 | 2016 | 0 | ... | 1 | 12000.0 | 8 | 1 | 0.0 | 0 | 3000 | 1 | 0 | 0 |
| 3998 | 0 | 33000.0 | 1 | 3 | 750 | 4 | 0 | 0 | 2015 | 0 | ... | 1 | 36000.0 | 20 | 1 | 3000.0 | 0 | 3000 | 0 | 0 | 0 |
| 3999 | 0 | 14000.0 | 1 | 0 | 750 | 3 | 0 | 0 | 2008 | 0 | ... | 0 | 14000.0 | 14 | 1 | 0.0 | 1 | 2600 | 1 | 0 | 0 |
4000 rows × 46 columns
[15]:
test
[15]:
| fraud | vehicle_claim | driver_relationship_self | num_witnesses | policy_deductable | incident_day | policy_state_nv | policy_state_az | auto_year | policy_state_or | ... | authorities_contacted_police | total_claim_amount | incident_hour | policy_state_ca | injury_claim | authorities_contacted_ambulance | policy_annual_premium | customer_gender_male | driver_relationship_other | num_claims_past_year | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 8500.0 | 0 | 0 | 750 | 27 | 0 | 0 | 2014 | 0 | ... | 0 | 8500.0 | 15 | 1 | 0.0 | 0 | 3000 | 1 | 0 | 0 |
| 1 | 0 | 16000.0 | 1 | 1 | 750 | 2 | 0 | 0 | 2014 | 1 | ... | 1 | 41000.0 | 8 | 0 | 25000.0 | 0 | 3000 | 1 | 0 | 0 |
| 2 | 0 | 7000.0 | 1 | 0 | 750 | 19 | 0 | 0 | 2014 | 0 | ... | 0 | 7000.0 | 9 | 1 | 0.0 | 0 | 3000 | 1 | 0 | 0 |
| 3 | 0 | 17500.0 | 0 | 0 | 750 | 1 | 0 | 0 | 2020 | 0 | ... | 0 | 17500.0 | 4 | 1 | 0.0 | 0 | 3000 | 1 | 0 | 0 |
| 4 | 0 | 17000.0 | 0 | 0 | 750 | 17 | 1 | 0 | 2018 | 0 | ... | 1 | 17000.0 | 18 | 0 | 0.0 | 0 | 3000 | 1 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 995 | 0 | 11000.0 | 1 | 0 | 750 | 4 | 0 | 0 | 2014 | 1 | ... | 1 | 11000.0 | 16 | 0 | 0.0 | 0 | 2850 | 1 | 0 | 0 |
| 996 | 0 | 14000.0 | 1 | 0 | 750 | 17 | 0 | 1 | 2019 | 0 | ... | 1 | 14000.0 | 22 | 0 | 0.0 | 0 | 3000 | 1 | 0 | 0 |
| 997 | 0 | 40000.0 | 1 | 1 | 750 | 7 | 0 | 0 | 2019 | 0 | ... | 1 | 55000.0 | 18 | 1 | 15000.0 | 0 | 3000 | 1 | 0 | 0 |
| 998 | 0 | 40000.0 | 1 | 1 | 750 | 3 | 0 | 0 | 2018 | 0 | ... | 0 | 40000.0 | 18 | 0 | 0.0 | 1 | 3000 | 1 | 0 | 1 |
| 999 | 1 | 35000.0 | 1 | 2 | 750 | 21 | 1 | 0 | 2016 | 0 | ... | 1 | 35000.0 | 16 | 0 | 0.0 | 0 | 3000 | 1 | 0 | 1 |
1000 rows × 46 columns
Resolve class imbalance using SMOTE
To handle the imbalance, we can over-sample (i.e. upsample) the minority class using SMOTE (Synthetic Minority Over-sampling Technique). After installing the imbalanced-learn module, if you receive an ImportError when importing SMOTE, then try restarting the kernel.
Gender balance before SMOTE
[ ]:
gender = train["customer_gender_female"]
gender.value_counts()
Gender balance after SMOTE
[ ]:
sm = SMOTE(random_state=42)
train_data_upsampled, gender_res = sm.fit_resample(train, gender)
train_data_upsampled["customer_gender_female"].value_counts()
Train new model
[ ]:
train_data_upsampled.to_csv("data/upsampled_train.csv", index=False)
s3_client.upload_file(
Filename="data/upsampled_train.csv",
Bucket=bucket,
Key=f"{prefix}/data/train/upsampled/train.csv",
)
[ ]:
xgb_estimator = XGBoost(
entry_point="xgboost_starter_script.py",
hyperparameters=hyperparameters,
role=sagemaker_role,
instance_count=train_instance_count,
instance_type=train_instance_type,
framework_version="1.0-1",
)
[ ]:
if 'training_job_2_name' not in locals():
xgb_estimator.fit(inputs = {'train': train_data_upsampled_s3_path})
training_job_2_name = xgb_estimator.latest_training_job.job_name
%store training_job_2_name
else:
print(f'Using previous training job: {training_job_2_name}')
Register artifacts
[ ]:
training_job_2_info = sagemaker_boto_client.describe_training_job(
TrainingJobName=training_job_2_name
)
Code artifact
[ ]:
# return any existing artifact which match the our training job's code arn
code_s3_uri = training_job_2_info["HyperParameters"]["sagemaker_submit_directory"]
list_response = list(
sagemaker.lineage.artifact.Artifact.list(
source_uri=code_s3_uri, sagemaker_session=sagemaker_session
)
)
# use existing arifact if it's already been created, otherwise create a new artifact
if list_response:
code_artifact = list_response[0]
print(f"Using existing artifact: {code_artifact.artifact_arn}")
else:
code_artifact = sagemaker.lineage.artifact.Artifact.create(
artifact_name="TrainingScript",
source_uri=code_s3_uri,
artifact_type="Code",
sagemaker_session=sagemaker_session,
)
print(f"Create artifact {code_artifact.artifact_arn}: SUCCESSFUL")
Training data artifact
[ ]:
training_data_s3_uri = training_job_2_info["InputDataConfig"][0]["DataSource"]["S3DataSource"][
"S3Uri"
]
list_response = list(
sagemaker.lineage.artifact.Artifact.list(
source_uri=training_data_s3_uri, sagemaker_session=sagemaker_session
)
)
if list_response:
training_data_artifact = list_response[0]
print(f"Using existing artifact: {training_data_artifact.artifact_arn}")
else:
training_data_artifact = sagemaker.lineage.artifact.Artifact.create(
artifact_name="TrainingData",
source_uri=training_data_s3_uri,
artifact_type="Dataset",
sagemaker_session=sagemaker_session,
)
print(f"Create artifact {training_data_artifact.artifact_arn}: SUCCESSFUL")
Model artifact
[ ]:
trained_model_s3_uri = training_job_2_info["ModelArtifacts"]["S3ModelArtifacts"]
list_response = list(
sagemaker.lineage.artifact.Artifact.list(
source_uri=trained_model_s3_uri, sagemaker_session=sagemaker_session
)
)
if list_response:
model_artifact = list_response[0]
print(f"Using existing artifact: {model_artifact.artifact_arn}")
else:
model_artifact = sagemaker.lineage.artifact.Artifact.create(
artifact_name="TrainedModel",
source_uri=trained_model_s3_uri,
artifact_type="Model",
sagemaker_session=sagemaker_session,
)
print(f"Create artifact {model_artifact.artifact_arn}: SUCCESSFUL")
Set artifact associations
[ ]:
trial_component = sagemaker_boto_client.describe_trial_component(
TrialComponentName=training_job_2_name + "-aws-training-job"
)
trial_component_arn = trial_component["TrialComponentArn"]
Input artifacts
[ ]:
input_artifacts = [code_artifact, training_data_artifact]
for a in input_artifacts:
try:
sagemaker.lineage.association.Association.create(
source_arn=a.artifact_arn,
destination_arn=trial_component_arn,
association_type="ContributedTo",
sagemaker_session=sagemaker_session,
)
print(f"Associate {trial_component_arn} and {a.artifact_arn}: SUCCEESFUL\n")
except:
print(f"Association already exists between {trial_component_arn} and {a.artifact_arn}.\n")
Output artifacts
[ ]:
output_artifacts = [model_artifact]
for artifact_arn in output_artifacts:
try:
sagemaker.lineage.association.Association.create(
source_arn=a.artifact_arn,
destination_arn=trial_component_arn,
association_type="Produced",
sagemaker_session=sagemaker_session,
)
print(f"Associate {trial_component_arn} and {a.artifact_arn}: SUCCEESFUL\n")
except:
print(f"Association already exists between {trial_component_arn} and {a.artifact_arn}.\n")
Analyze the second model for bias and explainability
overview
Amazon SageMaker Clarify provides tools to help explain how machine learning (ML) models make predictions. These tools can help ML modelers and developers and other internal stakeholders understand model characteristics as a whole prior to deployment and to debug predictions provided by the model after it’s deployed. Transparency about how ML models arrive at their predictions is also critical to consumers and regulators who need to trust the model predictions if they are going to accept the decisions based on them. SageMaker Clarify uses a model-agnostic feature attribution approach, which you can used to understand why a model made a prediction after training and to provide per-instance explanation during inference. The implementation includes a scalable and efficient implementation of SHAP (see paper), based on the concept of a Shapley value from the field of cooperative game theory that assigns each feature an importance value for a particular prediction.
Create model from estimator
[ ]:
model_matches = sagemaker_boto_client.list_models(NameContains=model_2_name)['Models']
if not model_matches:
model_2 = sagemaker_session.create_model_from_job(
name=model_2_name,
training_job_name=training_job_2_info['TrainingJobName'],
role=sagemaker_role,
image_uri=training_job_2_info['AlgorithmSpecification']['TrainingImage'])
%store model_2_name
else:
print(f"Model {model_2_name} already exists.")
Check for data set bias and model bias
With SageMaker, we can check for pre-training and post-training bias. Pre-training metrics show pre-existing bias in that data, while post-training metrics show bias in the predictions from the model. Using the SageMaker SDK, we can specify which groups we want to check bias across and which metrics we’d like to show.
To run the full Clarify job, you must un-comment the code in the cell below. Running the job will take ~15 minutes. If you wish to save time, you can view the results in the next cell after which loads a pre-generated output if no bias job was run.
[ ]:
clarify_processor = sagemaker.clarify.SageMakerClarifyProcessor(
role=sagemaker_role,
instance_count=1,
instance_type="ml.c4.xlarge",
sagemaker_session=sagemaker_session,
)
bias_data_config = sagemaker.clarify.DataConfig(
s3_data_input_path=train_data_upsampled_s3_path,
s3_output_path=bias_report_2_output_path,
label="fraud",
headers=train.columns.to_list(),
dataset_type="text/csv",
)
model_config = sagemaker.clarify.ModelConfig(
model_name=model_2_name,
instance_type=train_instance_type,
instance_count=1,
accept_type="text/csv",
)
predictions_config = sagemaker.clarify.ModelPredictedLabelConfig(probability_threshold=0.5)
bias_config = sagemaker.clarify.BiasConfig(
label_values_or_threshold=[0],
facet_name="customer_gender_female",
facet_values_or_threshold=[1],
)
# # un-comment the code below to run the whole job
# if 'clarify_bias_job_2_name' not in locals():
# clarify_processor.run_bias(
# data_config=bias_data_config,
# bias_config=bias_config,
# model_config=model_config,
# model_predicted_label_config=predictions_config,
# pre_training_methods='all',
# post_training_methods='all')
# clarify_bias_job_2_name = clarify_processor.latest_job.name
# %store clarify_bias_job_2_name
# else:
# print(f'Clarify job {clarify_bias_job_2_name} has already run successfully.')
View results of Clarify job
overview
Running Clarify on your dataset or model can take ~15 minutes. If you don’t have time to run the job, you can view the pre-generated results included with this demo. Otherwise, you can run the job by un-commenting the code in the cell above.
[ ]:
if "clarify_bias_job_2_name" in locals():
s3_client.download_file(
Bucket=bucket,
Key=f"{prefix}/clarify-output/bias-2/analysis.json",
Filename="clarify_output/bias_2/analysis.json",
)
print(f"Downloaded analysis from previous Clarify job: {clarify_bias_job_2_name}\n")
else:
print(f"Loading pre-generated analysis file...\n")
with open("clarify_output/bias_1/analysis.json", "r") as f:
bias_analysis = json.load(f)
results = bias_analysis["pre_training_bias_metrics"]["facets"]["customer_gender_female"][0][
"metrics"
][1]
print(json.dumps(results, indent=4))
with open("clarify_output/bias_2/analysis.json", "r") as f:
bias_analysis = json.load(f)
results = bias_analysis["pre_training_bias_metrics"]["facets"]["customer_gender_female"][0][
"metrics"
][1]
print(json.dumps(results, indent=4))
Configure and run explainability job
overview
To run the full Clarify job, you must un-comment the code in the cell below. Running the job will take ~15 minutes. If you wish to save time, you can view the results in the next cell after which loads a pre-generated output if no explainability job was run.
[ ]:
model_config = sagemaker.clarify.ModelConfig(
model_name=model_2_name,
instance_type=train_instance_type,
instance_count=1,
accept_type="text/csv",
)
shap_config = sagemaker.clarify.SHAPConfig(
baseline=[train.median().values[1:].tolist()], num_samples=100, agg_method="mean_abs"
)
explainability_data_config = sagemaker.clarify.DataConfig(
s3_data_input_path=train_data_upsampled_s3_path,
s3_output_path=explainability_output_path,
label="fraud",
headers=train.columns.to_list(),
dataset_type="text/csv",
)
# un-comment the code below to run the whole job
# if 'clarify_expl_job_name' not in locals():
# clarify_processor.run_explainability(
# data_config=explainability_data_config,
# model_config=model_config,
# explainability_config=shap_config)
# clarify_expl_job_name = clarify_processor.latest_job.name
# %store clarify_expl_job_name
# else:
# print(f'Clarify job {clarify_expl_job_name} has already run successfully.')
View Clarify explainability results (shortcut)
Running Clarify on your dataset or model can take ~15 minutes. If you don’t have time to run the job, you can view the pre-generated results included with this demo. Otherwise, you can run the job by un-commenting the code in the cell above.
[32]:
if "clarify_expl_job_name" in locals():
s3_client.download_file(
Bucket=bucket,
Key=f"{prefix}/clarify-output/explainability/analysis.json",
Filename="clarify_output/explainability/analysis.json",
)
print(f"Downloaded analysis from previous Clarify job: {clarify_expl_job_name}\n")
else:
print(f"Loading pre-generated analysis file...\n")
with open("clarify_output/explainability/analysis.json", "r") as f:
analysis_result = json.load(f)
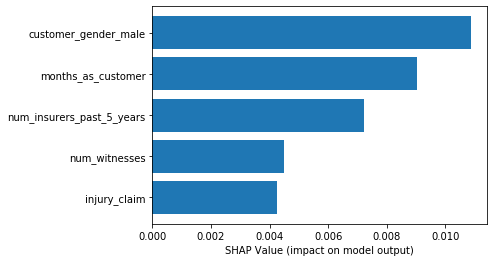
shap_values = pd.DataFrame(analysis_result["explanations"]["kernel_shap"]["label0"])
importances = shap_values["global_shap_values"].sort_values(ascending=False)
fig, ax = plt.subplots()
n = 5
y_pos = np.arange(n)
importance_scores = importances.values[:n]
y_label = importances.index[:n]
ax.barh(y_pos, importance_scores, align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels(y_label)
ax.invert_yaxis()
ax.set_xlabel("SHAP Value (impact on model output)");
Loading pre-generated analysis file...
To see the autogenerated SageMaker Clarify report, run the following code and use the output link to open the report.
[102]:
from IPython.display import FileLink, FileLinks
display(
"Click link below to view the SageMaker Clarify report", FileLink("clarify_output/report.pdf")
)
'Click link below to view the SageMaker Clarify report'
What is SHAP?
SHAP is the method used for calculating explanations in this solution. Unlike other feature attribution methods, such as single feature permutation, SHAP tries to disentangle the effect of a single feature by looking at all possible combinations of features.
SHAP (Lundberg et al. 2017) stands for SHapley Additive exPlanations. ‘Shapley’ relates to a game theoretic concept called Shapley values that is used to create the explanations. A Shapley value describes the marginal contribution of each ‘player’ when considering all possible ‘coalitions’. Using this in a machine learning context, a Shapley value describes the marginal contribution of each feature when considering all possible sets of features. ‘Additive’ relates to the fact that these Shapley values can be summed together to give the final model prediction.
As an example, we might start off with a baseline credit default risk of 10%. Given a set of features, we can calculate the Shapley value for each feature. Summing together all the Shapley values, we might obtain a cumulative value of +30%. Given the same set of features, we therefore expect our model to return a credit default risk of 40% (i.e. 10% + 30%).
Create Model Package for the Second Trained Model
overview
[ ]:
model_metrics_report = {"binary_classification_metrics": {}}
for metric in training_job_2_info["FinalMetricDataList"]:
stat = {metric["MetricName"]: {"value": metric["Value"], "standard_deviation": "NaN"}}
model_metrics_report["binary_classification_metrics"].update(stat)
with open("training_metrics.json", "w") as f:
json.dump(model_metrics_report, f)
metrics_s3_key = (
f"{prefix}/training_jobs/{training_job_2_info['TrainingJobName']}/training_metrics.json"
)
s3_client.upload_file(Filename="training_metrics.json", Bucket=bucket, Key=metrics_s3_key)
[ ]:
mp_inference_spec = InferenceSpecification().get_inference_specification_dict(
ecr_image=training_job_2_info["AlgorithmSpecification"]["TrainingImage"],
supports_gpu=False,
supported_content_types=["text/csv"],
supported_mime_types=["text/csv"],
)
mp_inference_spec["InferenceSpecification"]["Containers"][0]["ModelDataUrl"] = training_job_2_info[
"ModelArtifacts"
]["S3ModelArtifacts"]
[ ]:
model_metrics = {
"ModelQuality": {
"Statistics": {
"ContentType": "application/json",
"S3Uri": f"s3://{bucket}/{metrics_s3_key}",
}
},
"Bias": {
"Report": {
"ContentType": "application/json",
"S3Uri": f"{explainability_output_path}/analysis.json",
}
},
}
[ ]:
mp_input_dict = {
"ModelPackageGroupName": mpg_name,
"ModelPackageDescription": "XGBoost classifier to detect insurance fraud with SMOTE.",
"ModelApprovalStatus": "PendingManualApproval",
"ModelMetrics": model_metrics,
}
mp_input_dict.update(mp_inference_spec)
mp2_response = sagemaker_boto_client.create_model_package(**mp_input_dict)
mp2_arn = mp2_response["ModelPackageArn"]
%store mp2_arn
[ ]:
mp_info = sagemaker_boto_client.describe_model_package(
ModelPackageName=mp2_response["ModelPackageArn"]
)
mp_status = mp_info["ModelPackageStatus"]
while mp_status not in ["Completed", "Failed"]:
time.sleep(5)
mp_info = sagemaker_boto_client.describe_model_package(
ModelPackageName=mp2_response["ModelPackageArn"]
)
mp_status = mp_info["ModelPackageStatus"]
print(f"model package status: {mp_status}")
print(f"model package status: {mp_status}")
View both models in the registry
[ ]:
sagemaker_boto_client.list_model_packages(ModelPackageGroupName=mpg_name)["ModelPackageSummaryList"]
Next Notebook: Deploy Model, Run Predictions
[ ]: