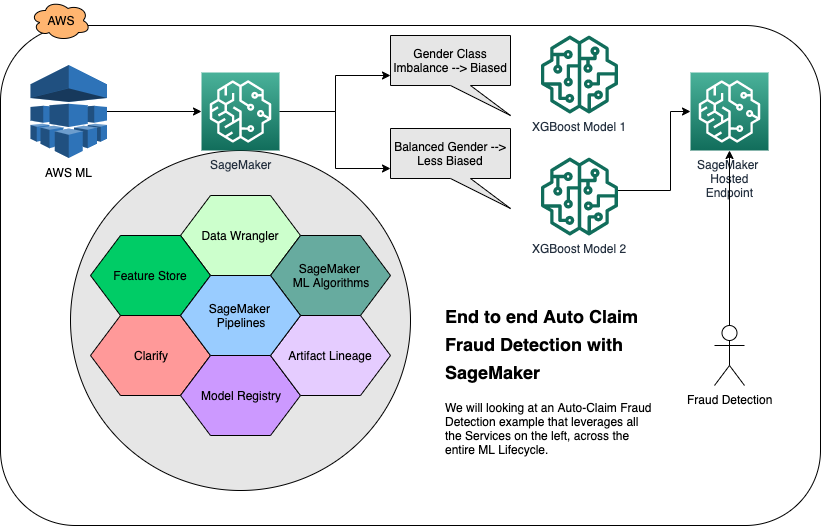
SageMaker End to End Solutions: Fraud Detection for Automobile Claims
Overview
`Notebook 0 : Overview, Architecture, and Data Exploration <./0-AutoClaimFraudDetection.ipynb>`__
`Business Problem <#business-problem>`__
`Technical Solution <#nb0-solution>`__
`Solution Components <#nb0-components>`__
`Solution Architecture <#nb0-architecture>`__
`DataSets and Exploratory Data Analysis <#nb0-data-explore>`__
`Exploratory Data Science and Operational ML workflows <#nb0-workflows>`__
`The ML Life Cycle: Detailed View <#nb0-ml-lifecycle>`__
Architecture
Getting started
DataSets
SageMaker Feature Store
Create train and test datasets
Notebook 2: Train, Check Bias, Tune, Record Lineage, and Register a Model
Architecture
Train a model using XGBoost
Model lineage with artifacts and associations
Evaluate the model for bias with Clarify
Deposit Model and Lineage in SageMaker Model Registry
Notebook 3: Mitigate Bias, Train New Model, Store in Registry
Architecture
Develop a second model
Analyze the Second Model for Bias
View Results of Clarify Bias Detection Job
Configure and Run Clarify Explainability Job
Create Model Package for second trained model
Architecture
Deploy an approved model and Run Inference via Feature Store
Create a Predictor
Run Predictions from Online FeatureStore
Notebook 5 : Create and Run an End-to-End Pipeline to Deploy the Model
Architecture
Create an Automated Pipeline
Clean up
Overview, Architecture, and Data Exploration
In this overview notebook, we will address business problems regarding auto insurance fraud, technical solutions, explore dataset, solution architecture, and scope the machine learning (ML) life cycle.
Business Problem
“Auto insurance fraud ranges from misrepresenting facts on insurance applications and inflating insurance claims to staging accidents and submitting claim forms for injuries or damage that never occurred, to false reports of stolen vehicles. Fraud accounted for between 15 percent and 17 percent of total claims payments for auto insurance bodily injury in 2012, according to an Insurance Research Council (IRC) study. The study estimated that between \(\$5.6\) billion and \(\$7.7\) billion
was fraudulently added to paid claims for auto insurance bodily injury payments in 2012, compared with a range of \(\$4.3\) billion to \(\$5.8\) billion in 2002. ” source: Insurance Information Institute
As you review the notebooks and the architectures presented at each stage of the ML life cycle, you will see how you can leverage SageMaker services and features to enhance your effectiveness as a data scientist, as a machine learning engineer, and as an ML Ops Engineer.
We will then do data exploration on the synthetically generated datasets for Customers and Claims.
Then, we will provide an overview of the technical solution by examining the Solution Components and the Solution Architecture. We will be motivated by the need to accomplish new tasks in ML by examining a detailed view of the Machine Learning Life-cycle, recognizing the separation of exploratory data science and operationalizing an ML worklfow.
Car Insurance Claims: Data Sets and Problem Domain
The inputs for building our model and workflow are two tables of insurance data: a claims table and a customers table. This data was synthetically generated is provided to you in its raw state for pre-processing with SageMaker Data Wrangler. However, completing the Data Wragnler step is not required to continue with the rest of this notebook. If you wish, you may use the claims_preprocessed.csv and customers_preprocessed.csv in the data directory as they are exact copies of what Data
Wragnler would output.
Technical Solution
In this introduction, you will look at the technical architecture and solution components to build a solution for predicting fraudulent insurance claims and deploy it using SageMaker for real-time predictions. While a deployed model is the end-product of this notebook series, the purpose of this guide is to walk you through all the detailed stages of the machine learning (ML) lifecycle and show you what SageMaker servcies and features are there to support your activities in each stage.
Topics - Solution Components - Solution Architecture - Code Resources - ML lifecycle details - Manual/exploratory and automated workflows
Solution Components
The following SageMaker Services are used in this solution:
DataSets and Exploratory Visualizations
The dataset is synthetically generated and consists of customers and claims datasets. Here we will load them and do some exploratory visualizations.
[ ]:
!pip install seaborn==0.11.1
[ ]:
# Importing required libraries.
import pandas as pd
import numpy as np
import seaborn as sns # visualisation
import matplotlib.pyplot as plt # visualisation
%matplotlib inline
sns.set(color_codes=True)
df_claims = pd.read_csv("./data/claims_preprocessed.csv", index_col=0)
df_customers = pd.read_csv("./data/customers_preprocessed.csv", index_col=0)
[ ]:
print(df_claims.isnull().sum().sum())
print(df_customers.isnull().sum().sum())
This should return no null values in both of the datasets.
[3]:
# plot the bar graph customer gender
df_customers.customer_gender_female.value_counts(normalize=True).plot.bar()
plt.xticks([0, 1], ["Male", "Female"]);
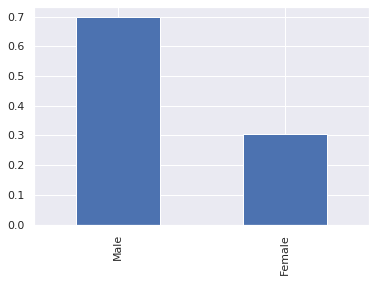
The dataset is heavily weighted towards male customers.
[4]:
# plot the bar graph of fraudulent claims
df_claims.fraud.value_counts(normalize=True).plot.bar()
plt.xticks([0, 1], ["Not Fraud", "Fraud"]);
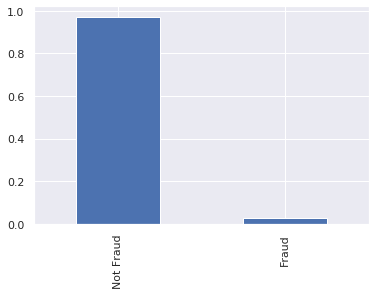
The overwhemling majority of claims are legitimate (i.e. not fraudulent).
[5]:
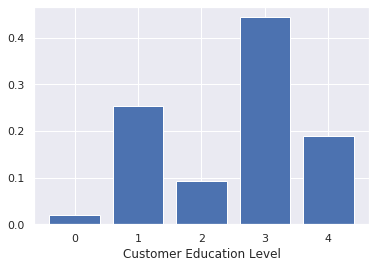
# plot the education categories
educ = df_customers.customer_education.value_counts(normalize=True, sort=False)
plt.bar(educ.index, educ.values)
plt.xlabel("Customer Education Level");
[6]:
# plot the total claim amounts
plt.hist(df_claims.total_claim_amount, bins=30)
plt.xlabel("Total Claim Amount")
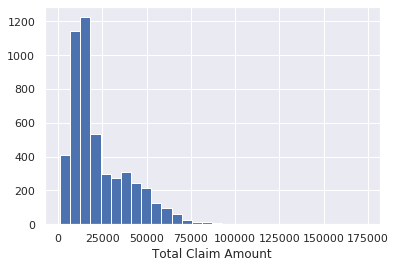
Majority of the total claim amounts are under $25,000.
[19]:
# plot the number of claims filed in the past year
df_customers.num_claims_past_year.hist(density=True)
plt.suptitle("Number of Claims in the Past Year")
plt.xlabel("Number of claims per year")
[19]:
Text(0.5, 0, 'Number of claims per year')
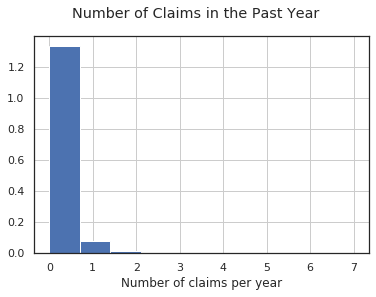
Most customers did not file any claims in the previous year, but some filed as many as 7 claims.
[8]:
sns.pairplot(
data=df_customers, vars=["num_insurers_past_5_years", "months_as_customer", "customer_age"]
);
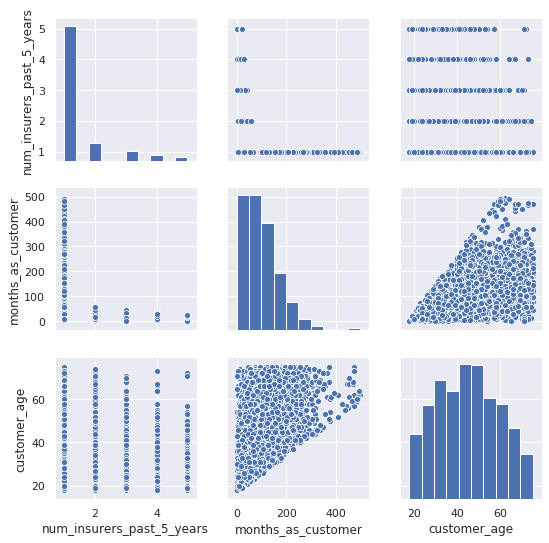
Understandably, the months_as_customer and customer_age are correlated with each other. A younger person have been driving for a smaller amount of time and therefore have a smaller potential for how long they might have been a customer.
We can also see that the num_insurers_past_5_years is negatively correlated with months_as_customer. If someone frequently jumped around to different insurers, then they probably spent less time as a customer of this insurer.
[9]:
df_combined = df_customers.join(df_claims)
sns.lineplot(x="num_insurers_past_5_years", y="fraud", data=df_combined);
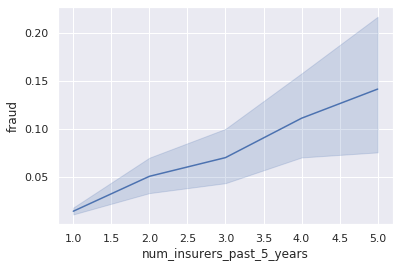
Fraud is positively correlated with having a greater number of insurers over the past 5 years. Customers who switched insurers more frequently also had more prevelance of fraud.
[10]:
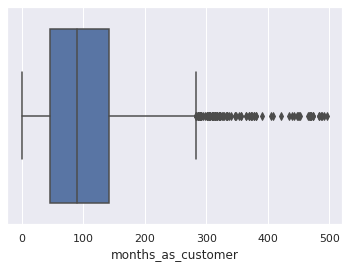
sns.boxplot(x=df_customers["months_as_customer"]);
[11]:
sns.boxplot(x=df_customers["customer_age"]);
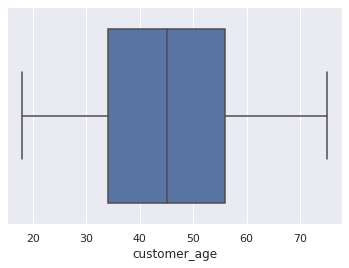
Our customers range from 18 to 75 years old.
[12]:
df_combined.groupby("customer_gender_female").mean()["fraud"].plot.bar()
plt.xticks([0, 1], ["Male", "Female"])
plt.suptitle("Fraud by Gender");
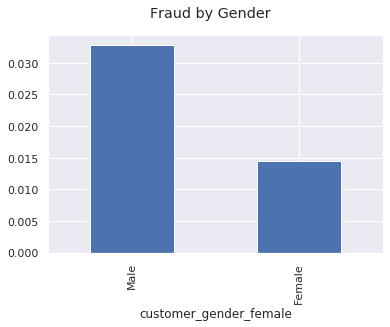
Fraudulent claims come disproportionately from male customers.
[13]:
# Creating a correlation matrix of fraud, gender, months as customer, and number of different insurers
cols = [
"fraud",
"customer_gender_male",
"customer_gender_female",
"months_as_customer",
"num_insurers_past_5_years",
]
corr = df_combined[cols].corr()
# plot the correlation matrix
sns.heatmap(corr, annot=True, cmap="Reds");
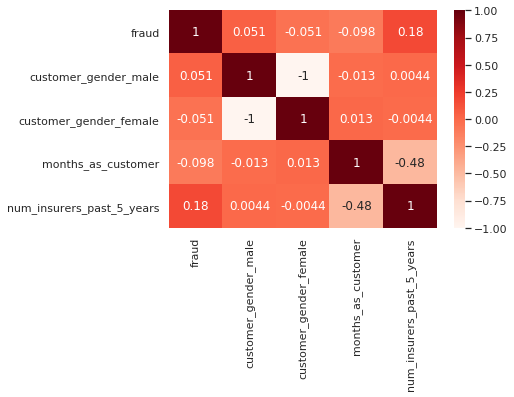
Fraud is correlated with having more insurers in the past 5 years, and negatively correlated with being a customer for a longer period of time. These go hand in hand and mean that long time customers are less likely to commit fraud.
Combined DataSets
We have been looking at the indivudual datasets, now let’s look at their combined view (join).
[14]:
import pandas as pd
df_combined = pd.read_csv("./data/claims_customer.csv")
[15]:
df_combined = df_combined.loc[:, ~df_combined.columns.str.contains("^Unnamed: 0")]
# get rid of an unwanted column
df_combined.head()
[15]:
| policy_id | incident_type_theft | policy_state_ca | policy_deductable | num_witnesses | policy_state_or | incident_month | customer_gender_female | num_insurers_past_5_years | customer_gender_male | ... | policy_state_id | incident_hour | vehicle_claim | fraud | incident_type_collision | policy_annual_premium | policy_state_az | policy_state_wa | collision_type_rear | collision_type_front | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1675 | 0 | 0 | 750 | 0 | 0 | 2 | 0 | 1 | 0 | ... | 0 | 20 | 12000.0 | 0 | 0 | 3000 | 1 | 0 | 0 | 0 |
| 1 | 9 | 0 | 0 | 750 | 0 | 0 | 9 | 0 | 1 | 1 | ... | 0 | 15 | 18500.0 | 0 | 1 | 3000 | 0 | 0 | 0 | 0 |
| 2 | 1687 | 0 | 1 | 750 | 0 | 0 | 7 | 1 | 1 | 0 | ... | 0 | 16 | 17500.0 | 0 | 1 | 3000 | 0 | 0 | 0 | 0 |
| 3 | 1687 | 0 | 1 | 750 | 0 | 0 | 7 | 0 | 1 | 1 | ... | 0 | 16 | 17500.0 | 0 | 1 | 3000 | 0 | 0 | 0 | 0 |
| 4 | 1692 | 0 | 0 | 750 | 2 | 0 | 6 | 1 | 1 | 0 | ... | 0 | 8 | 21500.0 | 0 | 1 | 2800 | 1 | 0 | 0 | 1 |
5 rows × 47 columns
[16]:
df_combined.describe()
[16]:
| policy_id | incident_type_theft | policy_state_ca | policy_deductable | num_witnesses | policy_state_or | incident_month | customer_gender_female | num_insurers_past_5_years | customer_gender_male | ... | policy_state_id | incident_hour | vehicle_claim | fraud | incident_type_collision | policy_annual_premium | policy_state_az | policy_state_wa | collision_type_rear | collision_type_front | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 20000.00000 | 20000.000000 | 20000.0000 | 20000.00000 | 20000.000000 | 20000.000000 | 20000.000000 | 20000.000000 | 20000.000000 | 20000.000000 | ... | 20000.00000 | 20000.000000 | 20000.000000 | 20000.000000 | 20000.000000 | 20000.000000 | 20000.000000 | 20000.000000 | 20000.000000 | 20000.000000 |
| mean | 2500.50000 | 0.048200 | 0.6204 | 751.13000 | 0.866100 | 0.070000 | 6.713200 | 0.372400 | 1.412200 | 0.576500 | ... | 0.02730 | 11.786800 | 17426.083700 | 0.030000 | 0.857200 | 2925.400000 | 0.113600 | 0.121000 | 0.220900 | 0.425400 |
| std | 1443.41173 | 0.214194 | 0.4853 | 13.57322 | 1.097921 | 0.255153 | 3.654396 | 0.483456 | 0.897291 | 0.494125 | ... | 0.16296 | 5.337918 | 10043.773599 | 0.170591 | 0.349878 | 143.516096 | 0.317333 | 0.326135 | 0.414864 | 0.494416 |
| min | 1.00000 | 0.000000 | 0.0000 | 750.00000 | 0.000000 | 0.000000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | ... | 0.00000 | 0.000000 | 1000.000000 | 0.000000 | 0.000000 | 2150.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 1250.75000 | 0.000000 | 0.0000 | 750.00000 | 0.000000 | 0.000000 | 3.000000 | 0.000000 | 1.000000 | 0.000000 | ... | 0.00000 | 8.000000 | 10474.250000 | 0.000000 | 1.000000 | 2900.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 50% | 2500.50000 | 0.000000 | 1.0000 | 750.00000 | 0.000000 | 0.000000 | 7.000000 | 0.000000 | 1.000000 | 1.000000 | ... | 0.00000 | 12.000000 | 15000.000000 | 0.000000 | 1.000000 | 3000.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 75% | 3750.25000 | 0.000000 | 1.0000 | 750.00000 | 2.000000 | 0.000000 | 10.000000 | 1.000000 | 1.000000 | 1.000000 | ... | 0.00000 | 16.000000 | 22005.500000 | 0.000000 | 1.000000 | 3000.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 |
| max | 5000.00000 | 1.000000 | 1.0000 | 1100.00000 | 5.000000 | 1.000000 | 12.000000 | 1.000000 | 5.000000 | 1.000000 | ... | 1.00000 | 23.000000 | 51051.000000 | 1.000000 | 1.000000 | 3000.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
8 rows × 47 columns
Let’s explore any unique, missing, or large percentage category in the combined dataset.
[17]:
combined_stats = []
for col in df_combined.columns:
combined_stats.append(
(
col,
df_combined[col].nunique(),
df_combined[col].isnull().sum() * 100 / df_combined.shape[0],
df_combined[col].value_counts(normalize=True, dropna=False).values[0] * 100,
df_combined[col].dtype,
)
)
stats_df = pd.DataFrame(
combined_stats,
columns=["feature", "unique_values", "percent_missing", "percent_largest_category", "datatype"],
)
stats_df.sort_values("percent_largest_category", ascending=False)
[17]:
| feature | unique_values | percent_missing | percent_largest_category | datatype | |
|---|---|---|---|---|---|
| 3 | policy_deductable | 8 | 0.0 | 98.94 | int64 |
| 28 | authorities_contacted_ambulance | 2 | 0.0 | 97.45 | int64 |
| 37 | policy_state_id | 2 | 0.0 | 97.27 | int64 |
| 35 | authorities_contacted_fire | 2 | 0.0 | 97.20 | int64 |
| 40 | fraud | 2 | 0.0 | 97.00 | int64 |
| 36 | driver_relationship_other | 2 | 0.0 | 96.06 | int64 |
| 16 | driver_relationship_child | 2 | 0.0 | 95.49 | int64 |
| 27 | policy_state_nv | 2 | 0.0 | 95.23 | int64 |
| 1 | incident_type_theft | 2 | 0.0 | 95.18 | int64 |
| 23 | num_claims_past_year | 8 | 0.0 | 93.28 | int64 |
| 5 | policy_state_or | 2 | 0.0 | 93.00 | int64 |
| 17 | driver_relationship_spouse | 2 | 0.0 | 91.09 | int64 |
| 33 | incident_type_breakin | 2 | 0.0 | 90.54 | int64 |
| 43 | policy_state_az | 2 | 0.0 | 88.64 | int64 |
| 44 | policy_state_wa | 2 | 0.0 | 87.90 | int64 |
| 20 | collision_type_na | 2 | 0.0 | 85.72 | int64 |
| 32 | driver_relationship_na | 2 | 0.0 | 85.72 | int64 |
| 41 | incident_type_collision | 2 | 0.0 | 85.72 | int64 |
| 13 | collision_type_side | 2 | 0.0 | 78.91 | int64 |
| 45 | collision_type_rear | 2 | 0.0 | 77.91 | int64 |
| 8 | num_insurers_past_5_years | 5 | 0.0 | 77.68 | int64 |
| 34 | authorities_contacted_none | 2 | 0.0 | 75.86 | int64 |
| 42 | policy_annual_premium | 18 | 0.0 | 71.68 | int64 |
| 11 | authorities_contacted_police | 2 | 0.0 | 70.51 | int64 |
| 22 | driver_relationship_self | 2 | 0.0 | 68.36 | int64 |
| 29 | num_injuries | 5 | 0.0 | 67.46 | int64 |
| 7 | customer_gender_female | 2 | 0.0 | 62.76 | int64 |
| 2 | policy_state_ca | 2 | 0.0 | 62.04 | int64 |
| 9 | customer_gender_male | 2 | 0.0 | 57.65 | int64 |
| 46 | collision_type_front | 2 | 0.0 | 57.46 | int64 |
| 31 | police_report_available | 2 | 0.0 | 57.22 | int64 |
| 4 | num_witnesses | 6 | 0.0 | 51.58 | int64 |
| 26 | num_vehicles_involved | 7 | 0.0 | 46.32 | int64 |
| 15 | customer_education | 5 | 0.0 | 44.29 | int64 |
| 21 | incident_severity | 3 | 0.0 | 41.71 | int64 |
| 30 | policy_liability | 4 | 0.0 | 33.95 | int64 |
| 18 | injury_claim | 890 | 0.0 | 33.75 | float64 |
| 19 | incident_dow | 7 | 0.0 | 16.87 | int64 |
| 25 | auto_year | 20 | 0.0 | 13.86 | int64 |
| 6 | incident_month | 12 | 0.0 | 10.67 | int64 |
| 38 | incident_hour | 24 | 0.0 | 6.87 | int64 |
| 12 | incident_day | 31 | 0.0 | 3.79 | int64 |
| 14 | customer_age | 58 | 0.0 | 3.09 | int64 |
| 39 | vehicle_claim | 4621 | 0.0 | 1.44 | float64 |
| 10 | total_claim_amount | 4978 | 0.0 | 1.29 | float64 |
| 24 | months_as_customer | 387 | 0.0 | 0.77 | int64 |
| 0 | policy_id | 5000 | 0.0 | 0.02 | int64 |
[20]:
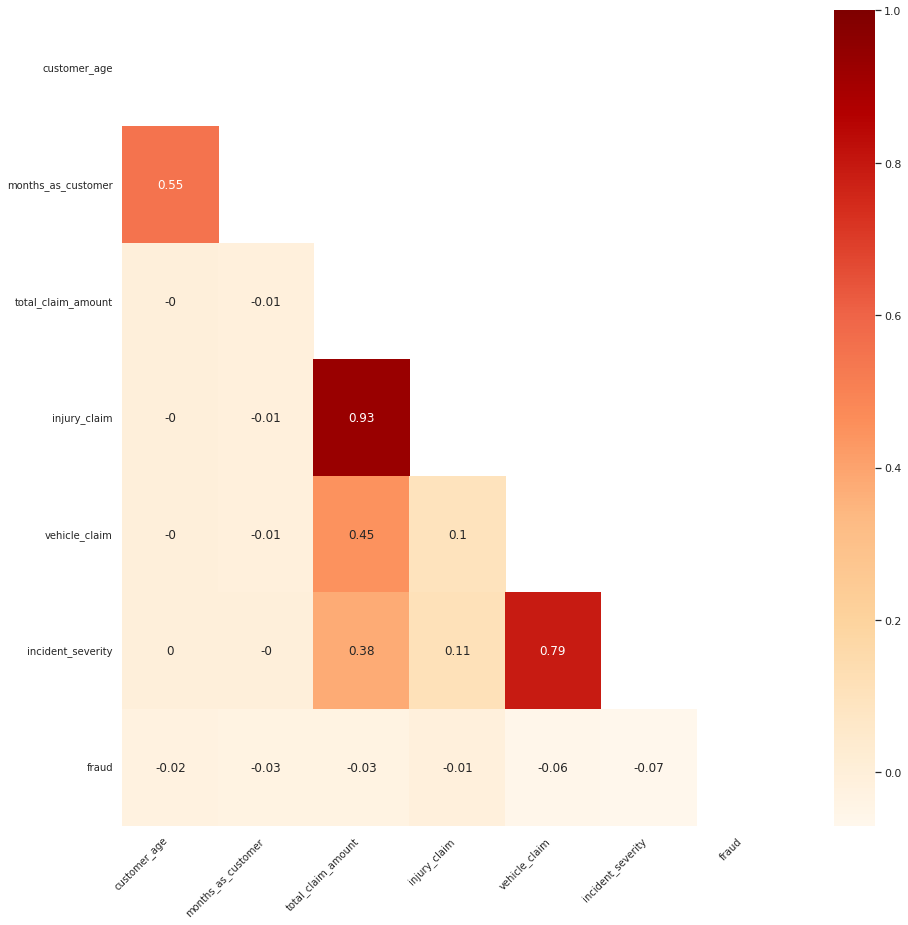
import matplotlib.pyplot as plt
import numpy as np
sns.set_style("white")
corr_list = [
"customer_age",
"months_as_customer",
"total_claim_amount",
"injury_claim",
"vehicle_claim",
"incident_severity",
"fraud",
]
corr_df = df_combined[corr_list]
corr = round(corr_df.corr(), 2)
fix, ax = plt.subplots(figsize=(15, 15))
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
ax = sns.heatmap(corr, mask=mask, ax=ax, annot=True, cmap="OrRd")
ax.set_xticklabels(ax.xaxis.get_ticklabels(), fontsize=10, ha="right", rotation=45)
ax.set_yticklabels(ax.yaxis.get_ticklabels(), fontsize=10, va="center", rotation=0)
plt.show()
Solution Architecture
We will go through 5 stages of ML and explore the solution architecture of SageMaker. Each of the sequancial notebooks will dive deep into corresponding ML stage.
Notebook 1: Data Preparation, Ingest, Transform, Preprocess, and Store in SageMaker Feature Store
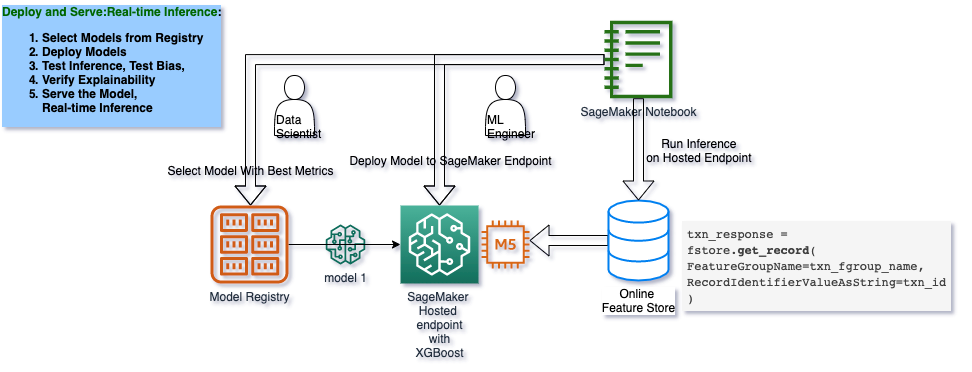
Notebook 2 and Notebook 3 : Train, Tune, Check Pre- and Post- Training Bias, Mitigate Bias, Re-train, and Deposit the Best Model to SageMaker Model Registry
Notebooks 4 : Load the Best Model from Registry, Deploy it to SageMaker Hosted Endpoint, and Make Predictions
Notebooks 5: End-to-End Pipeline - MLOps Pipeline to run an end-to-end automated workflow with all the design decisions made during manual/exploratory steps in previous notebooks.
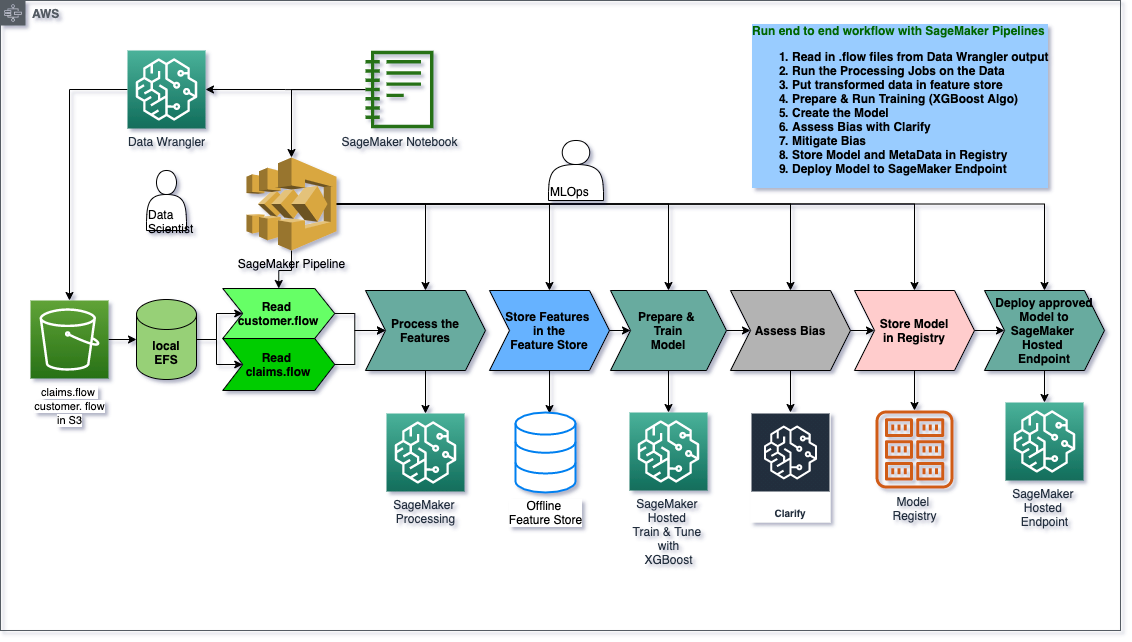
Code Resources
Stages
Our solution is split into the following stages of the ML Lifecycle, and each stage has it’s own notebook:
Use-case and Architecture: We take a high-level look at the use-case, solution components and architecture.
Data Prep and Store: We prepare a dataset for machine learning using SageMaker DataWrangler, create and deposit the datasets in a SageMaker FeatureStore. –> Architecture
Train, Assess Bias, Establish Lineage, Register Model: We detect possible pre-training and post-training bias, train and tune a XGBoost model using Amazon SageMaker, record Lineage in the Model Registry so we can later deploy it. –> Architecture
Mitigate Bias, Re-train, Register New Model: We mitigate bias, retrain a less biased model, store it in a Model Registry. –> Architecture
Deploy and Serve: We deploy the model to a Amazon SageMaker Hosted Endpoint and run realtime inference via the SageMaker Online Feature Store . –> Architecture
Create and Run an MLOps Pipeline: We then create a SageMaker Pipeline that ties together everything we have done so far, from outputs from Data Wrangler, Feature Store, Clarify , Model Registry and finally deployment to a SageMaker Hosted Endpoint. –> Architecture
Conclusion: We wrap things up and discuss how to clean up the solution.
The Exploratory Data Science and ML Ops Workflows
Exploratory Data Science and Scalable MLOps
Note that there are typically two workflows: a manual exploratory workflow and an automated workflow.
The exploratory, manual data science workflow is where experiments are conducted and various techniques and strategies are tested.
After you have established your data prep, transformations, featurizations and training algorithms, testing of various hyperparameters for model tuning, you can start with the automated workflow where you rely on MLOps or the ML Engineering part of your team to streamline the process, make it more repeatable and scalable by putting it into an automated pipeline.
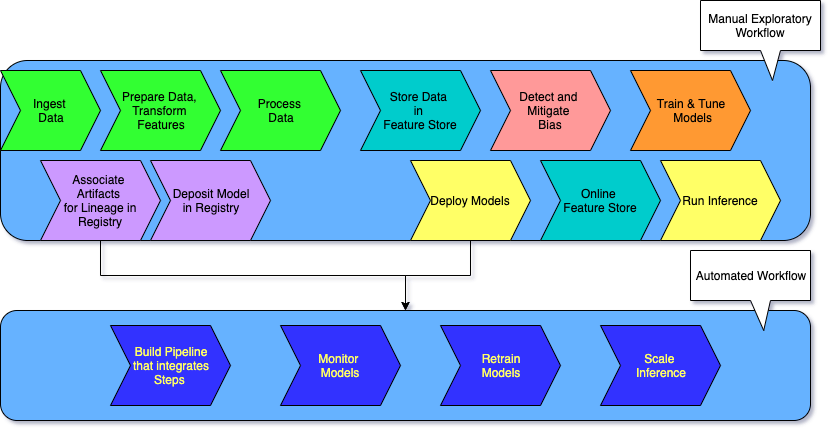
The ML Life Cycle: Detailed View
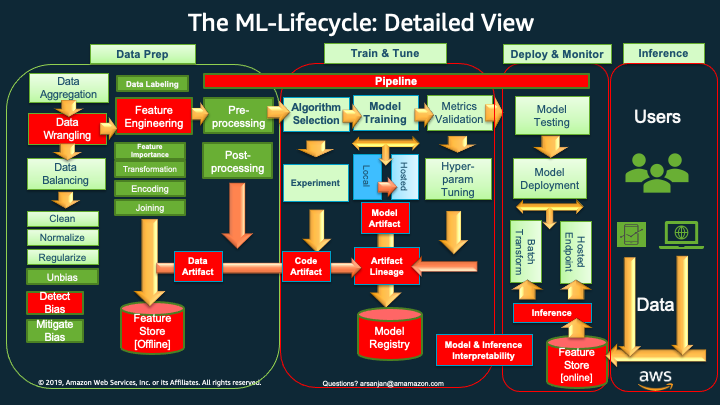
The Red Boxes and Icons represent comparatively newer concepts and tasks that are now deemed important to include and execute, in a production-oriented (versus research-oriented) and scalable ML lifecycle.
These newer lifecycle tasks and their corresponding, supporting AWS Services and features include:
`*Data Wrangling* <>`__: AWS Data Wrangler for cleaning, normalizing, transforming and encoding data, as well as join ing datasets. The outputs of Data Wrangler are code generated to work with SageMaker Processing, SageMaker Pipelines, SageMaker Feature Store or just a plain old python script with pandas,
Feature Engineering has always been done, but now with AWS Data Wrangler we can use a GUI based tool to do so and generate code for the next phases of the life-cycle.
`*Detect Bias* <>`__: Using AWS Clarify, in Data Prep or in Training we can detect pre-training and post-training bias, and eventually at Inference time provide Interpretability / Explainability of the inferences (e.g., which factors were most influential in coming up with the prediction)
`*Feature Store [Offline]* <>`__: Once we have done all of our feature engineering, the encoding and transformations, we can then standardize features, offline in AWS Feature Store, to be used as input features for training models.
`*Artifact Lineage* <>`__: Using AWS SageMaker’s Artifact Lineage features we can associate all the artifacts (data, models, parameters, etc.) with a trained model to produce meta data that can be stored in a Model Registry.
`*Model Registry* <>`__: AWS Model Registry stores the meta data around all artifacts that you have chosen to include in the process of creating your models, along with the model(s) themselves in a Model Registry. Later a human approval can be used to note that the model is good to be put into production. This feeds into the next phase of deploy and monitor .
`*Inference and the Online Feature Store* <>`__: For realtime inference, we can leverage a online AWS Feature Store we have created to get us single digit millisecond low latency and high throughput for serving our model with new incoming data.
`*Pipelines* <>`__: Once we have experimented and decided on the various options in the lifecycle (which transforms to apply to our features, imbalance or bias in the data, which algorithms to choose to train with, which hyper-parameters are giving us the best performance metrics, etc.) we can now automate the various tasks across the lifecycle using SageMaker Pipelines.
In this blog, we will show a pipeline that starts with the outputs of AWS Data Wrangler and ends with storing trained models in the Model Registry.
Typically, you could have a pipeline for data prep, one for training until model registry (which we are showing in the code associated with this blog) , one for inference, and one for re-training using SageMaker Monitor to detect model drift and data drift and trigger a re-training using , say an AWS Lambda function.
Next Notebook: Data Preparation, Process, and Store Features
[ ]: